

خرابی بهعنوان فرصت یادگیری در نگهداری
خرابی (Failure) در حوزه نگهداری (Maintenance) غالباً مفهومی ناخوشایند تلقی میشود. در صورت ازکارافتادگی تجهیزات، واحد نگهداری بهسرعت در معرض سرزنش قرار میگیرد. علاوه بر این، ارزیابی عملکرد بر اساس شاخصهای توقف تولید (Downtime Metrics) سبب میشود هر اختلال تجهیز بهعنوان خطایی بزرگ یا حتی «گناه نابخشودنی» تعبیر گردد.
بااینحال، چنین نگرشی هم ناکارآمد است و هم ناعادلانه؛ زیرا بسیاری از عوامل مؤثر اساساً خارج از کنترل تیم نگهداری قرار دارند. عواملی همچون سن دارایی (Asset Age)، طراحی (Design) یا خطای کاربر (User Error) نمونههایی از این موارد هستند. در واقع، خرابی میتواند بهعنوان منبعی ارزشمند برای یادگیری و بهبود در نظر گرفته شود.
بر اساس دیدگاه کارشناسان، برای دستیابی به بهبود مستمر، وجود خرابی اجتنابناپذیر و حتی ضروری است. خرابی فرصتی فراهم میآورد تا شناخت عمیقتری از سیستمهای تحت نگهداری حاصل شود، شیوه عملکرد آنها بهتر درک گردد و روشهای نگهداری مؤثرتر طراحی شوند.
در این مقاله، چگونگی بهرهگیری از سیستم FRACAS (Failure Reporting, Analysis, and Corrective Action System) بررسی میشود؛ سیستمی که امکان تبدیل خرابی به ابزاری برای ارتقای بهرهوری و افزایش ارزش کسبوکار را فراهم میسازد.
FRACAS چیست؟
FRACAS که مخفف Failure Reporting, Analysis, and Corrective Action System است، بهمعنای «سیستم گزارشدهی، تحلیل و اقدام اصلاحی خرابی» تعریف میشود. این سیستم بهعنوان یک چرخه بسته (Closed-loop Reporting System) طراحی شده است تا کنترل و حذف خرابی تجهیزات بهصورت نظاممند محقق گردد.
اجزای اصلی FRACAS شامل سه بخش کلیدی است:
گزارشدهی خرابی (Failure Reporting): شناسایی و ثبت دقیق خرابیهای دارایی.
تحلیل خرابی (Failure Analysis): استخراج دانش و بینش از رخدادهای خرابی بهمنظور درک عمیقتر علل آن.
اقدام اصلاحی (Failure Correction): انجام اقدامات اصلاحی برای رفع مشکلات موجود و پیشگیری از تکرار آنها.
یک سیستم FRACAS با اتکا به سوابق عملکرد تجهیزات (Equipment Performance History) قادر است الگوهای مشترک خرابی را شناسایی کند و مناسبترین راهکارها را برای مدیریت خرابیهای آتی ارائه دهد. افزون بر این، این سیستم نقش محوری در پشتیبانی و هدایت راهبرد نگهداری مبتنی بر قابلیت اطمینان (Reliability Maintenance Strategy) ایفا کرده و از مرحله طراحی (Design) تا زمانبندی فعالیتها (Scheduling) بهکار گرفته میشود.
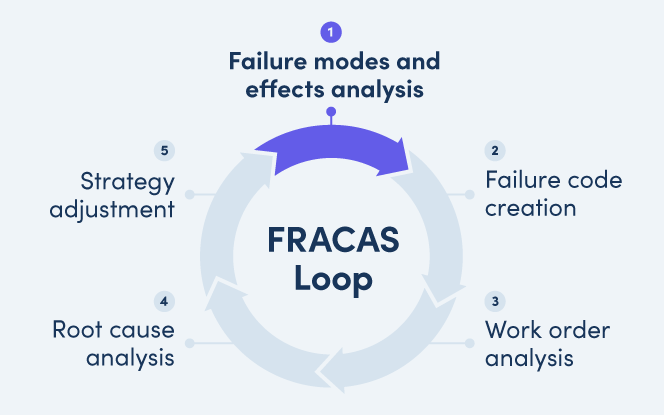
ایجاد یک FRACAS با بهرهگیری از چرخه FRACAS
چرخه FRACAS (FRACAS Loop) مجموعهای از فرایندهای ساختاریافته است که امکان گزارشدهی (Report)، تحلیل (Analyze) و اصلاح (Correct) خرابیها را فراهم میسازد. این چرخه بهصورت مداوم و تکرارشونده اجرا میشود تا خرابیها بهطور پیوسته شناسایی گردند، دانش حاصل از آنها استخراج شود و اقدامات اصلاحی مناسب برای جلوگیری از تکرار انجام گیرد.
اجزای اصلی چرخه FRACAS شامل پنج فعالیت کلیدی است:
تحلیل حالات و اثرات خرابی (Failure Modes and Effects Analysis – FMEA): شناسایی حالات بالقوه خرابی و ارزیابی پیامدهای آنها.
ایجاد کدهای خرابی (Failure Code Creation): تعریف و استانداردسازی کدهای خرابی بهمنظور یکپارچگی دادهها و سهولت تحلیل.
تحلیل دستورکارها (Work Order Analysis): بررسی دادههای حاصل از دستورکارهای نگهداری و تعمیرات برای شناسایی الگوهای تکراری.
تحلیل علل ریشهای خرابی (Root Cause Analysis – RCA): کشف دلایل بنیادین خرابیها بهمنظور طراحی اقدامات اصلاحی مؤثر.
تعدیل و اصلاح راهبرد (Strategy Adjustment): بازنگری و بهبود راهبردهای نگهداری بر اساس یافتههای تحلیلی.
بهکارگیری این چرخه موجب میشود سیستم FRACAS بهطور مستمر بهبود یافته و به ابزاری کارآمد برای ارتقای قابلیت اطمینان داراییها و افزایش بهرهوری سازمان تبدیل گردد.
تحلیل حالات و اثرات خرابی (FMEA)
تحلیل حالات و اثرات خرابی (Failure Modes and Effects Analysis – FMEA) ابزاری نظاممند است که بهمنظور شناسایی و مدیریت ریسکهای بالقوه ناشی از خرابی داراییها بهکار گرفته میشود. این روش در اصل برنامهای برای مواجهه با بدترین سناریوهای ممکن محسوب میشود. در FMEA فهرستی از تمامی راههایی که تجهیزات میتوانند دچار خرابی شوند تهیه میگردد، اثرات هر خرابی بر کل سیستم ارزیابی میشود و اقدامات لازم برای پیشگیری یا کاهش پیامدهای آن مشخص میگردد.
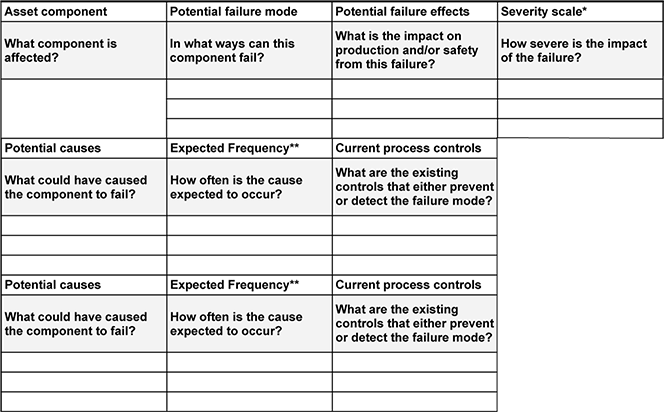
یک FMEA استاندارد معمولاً شامل ده جزء اصلی است:
اجزای دارایی (Asset Component): بخشها یا زیرسیستمهایی که احتمال خرابی در آنها وجود دارد.
حالات بالقوه خرابی (Potential Failure Modes): شیوهها یا مکانیزمهایی که از طریق آنها خرابی میتواند رخ دهد.
اثرات بالقوه خرابی (Potential Failure Effects): پیامدهای احتمالی خرابی بر عملکرد سیستم یا فرآیند.
شدت خرابی (Severity of Failure): میزان اهمیت یا وخامت اثر خرابی بر ایمنی، قابلیت اطمینان یا عملکرد.
علل بالقوه خرابی (Potential Causes): عوامل زمینهای یا شرایطی که احتمال وقوع خرابی را افزایش میدهند.
تواتر مورد انتظار خرابی (Expected Frequency of Failure): برآورد احتمال یا نرخ وقوع خرابی در طول زمان.
فرایندهای موجود برای شناسایی و پیشگیری (Current Processes to Detect and Prevent): کنترلها و رویههای جاری که برای کاهش احتمال وقوع خرابی یا کشف بهموقع آن بهکار میروند.
میزان قابلیت کشف خرابی (How Detectable the Failure Is): توانایی سیستم یا سازمان در شناسایی خرابی پیش از بروز اثرات جدی.
ریسک کلی خرابی (The Total Risk of the Failure): سطح کلی ریسک حاصل از ترکیب شدت، تواتر و قابلیت کشف خرابی.
اقدامات پیشنهادی (Recommended Action): اقدامات اصلاحی یا پیشگیرانه برای کاهش احتمال وقوع خرابی یا به حداقل رساندن اثرات آن.
استفاده از FMEA به سازمانها این امکان را میدهد که پیش از وقوع خرابیهای پرهزینه یا بحرانی، مخاطرات را شناسایی کرده و با تدوین اقدامات اصلاحی هدفمند، قابلیت اطمینان داراییها و ایمنی عملیات را بهطور چشمگیری افزایش دهند.
نقش FMEA در مدیریت خرابی
تحلیل حالات و اثرات خرابی (FMEA) بهعنوان خط مبنای مدیریت خرابی عمل میکند. این ابزار تمامی سناریوهای بالقوه خرابی را ترسیم مینماید تا امکان اولویتبندی اقدامات بر اساس معیارهایی همچون بحرانیبودن دارایی (Asset Criticality)، اثر خرابی (Impact)، تواتر وقوع (Frequency) و منابع موردنیاز (Resources Needed) فراهم گردد.
FMEA یک سند زنده (Living Document) محسوب میشود؛ به این معنا که با افزایش شناخت از خرابیهای رخداده در تأسیسات و روشهای حذف آنها (Eliminate Failures)، لازم است این سند بهطور مستمر بازنگری و بهروزرسانی شود تا تغییرات و یافتههای جدید منعکس گردد.
از همین رو، چرخه FRACAS (FRACAS Loop) همواره به این مرحله بازمیگردد و فرآیند FMEA را تکمیل و بهروزرسانی میکند. این بازگشت مداوم تضمین مینماید که رویکرد سازمان در مدیریت خرابیها پویا باقی بماند و متناسب با شرایط واقعی داراییها تکامل یابد.
ایجاد کد خرابی (Failure Code Creation)
کدهای خرابی (Failure Codes) ابزاری هستند که مشکلات تجهیزات را در قالب توصیفهای بسیار کوتاه و استاندارد بازنمایی میکنند. این کدها بهگونهای طراحی میشوند که قطعه (Part)، عیب (Defect) و علت (Cause) را بهطور همزمان مشخص سازند. برای نمونه، کد خرابی یک نوار نقاله انتقال با سرعت متغیر (Variable-Speed Transfer Conveyor) میتواند به شکل زیر تعریف شود:
Bearing — Wear — Lack of Lubrication (یاتاقان — سایش — کمبود روانکاری)
بهمنظور ایجاد و استفاده اثربخش از کدهای خرابی، رعایت چند اصل کلیدی (Best Practices) ضروری است:
تدوین رویه نامگذاری متمایز (Naming Convention): برای هر قطعه یک روش نامگذاری یکتا تعریف شود. اشتباه در شناسایی اجزای مشابه میتواند منجر به مشکلات بزرگتر در تحلیل و تصمیمگیری گردد.
طبقهبندی عیوب در ردههای مشخص (Categories): عیوب بهمنظور سادگی و شفافیت در دستههای استاندارد قرار گیرند؛ مانند سایش (Wear)، داغشدگی (Overheated) و موارد مشابه.
مدیریت کدهای ازپیشبارگذاریشده در CMMS: در صورت استفاده از کدهای پیشفرض موجود در سامانه مدیریت مکانیزه نگهداری و تعمیرات (CMMS – Computerized Maintenance Management System)، تنها رایجترین کدها نگهداری شوند. وجود بیش از ده کد معمولاً منجر به انتخاب گزینه «سایر (Other)» از سوی تکنسینها خواهد شد.
استفاده از FMEA برای ساخت فهرست اولیه: تحلیل حالات و اثرات خرابی (FMEA) بهعنوان مبنایی برای شناسایی کدهای کلیدی بهکار گرفته شود. این فهرست باید با مشارکت و تأیید (Validation) تکنسینها تکمیل گردد.
رهگیری کدهای خرابی در طول زمان: پایش مستمر این کدها امکان شناسایی روندها (Trends) را فراهم میآورد و نشان میدهد کدام خرابیها بیشترین تکرار و بیشترین زیان را ایجاد میکنند. بر این اساس میتوان برنامهای برای اولویتبندی و حذف (Prioritize & Eliminate) این خرابیها طراحی نمود.
استفاده صحیح از کدهای خرابی نهتنها موجب استانداردسازی دادههای نگهداری میشود، بلکه تحلیل روندها و تدوین راهبردهای مؤثر برای کاهش خرابیها را نیز تسهیل مینماید.
تحلیل دستورکارها (Work Order Analysis)
یک خرابی منفرد ممکن است تنها مزاحمتی جزئی ایجاد کند، اما تکرار همان نوع خرابی بهصورت متوالی به یک روند (Trend) تبدیل میشود که هزینههای سنگینی بر تیم نگهداری تحمیل میکند، برنامهریزیها را مختل میسازد و نارضایتی واحد تولید را در پی دارد. تحلیل دستورکارها (Work Order Analysis) بهعنوان یکی از مراحل چرخه FRACAS (FRACAS Loop) طراحی شده است تا این روندها شناسایی و برای حذف آنها اقدامات اصلاحی مناسب اتخاذ گردد.
یکی از سادهترین رویکردها برای تحلیل دادههای خرابی در دستورکارها، بررسی کدهای خرابی (Failure Codes) و تواتر وقوع آنها (Frequency) در یادداشتهای تکمیل دستورکار است.
بهعنوان مثال، فرض کنید چهار تجهیز مشابه طی شش ماه مجموعاً ۱۲ خرابی داشتهاند. با توجه به نقش حیاتی این ماشینها در تولید و درآمد و همچنین زمانبر بودن تعمیر آنها، نرخ بالای خرابی اهمیت ویژهای پیدا میکند. بررسی دادهها نشان میدهد که ۱۰ مورد از این ۱۲ خرابی ناشی از گیرپاژ یاتاقان (Bearing Seizure) بر اثر ناهمراستایی (Misalignment) بوده است. در نتیجه، نقطه تمرکز اقدامات اصلاحی بهوضوح مشخص میشود. علاوه بر این، یک خط مبنا (Baseline) برای سنجش اثربخشی اقدامات بهدست میآید. برای نمونه، اگر طی شش ماه بعد تعداد این نوع خرابیها به دو یا سه مورد کاهش یابد، میتوان اثبات کرد که اقدامات انجامشده مؤثر بودهاند.
روشهای متعددی برای بهرهگیری از دادههای خرابی در دستورکارها وجود دارد. برخی از این روشها در ادامه معرفی میشوند، هرچند برای آشنایی بیشتر با جزئیات و کاربردهای گستردهتر، مراجعه به راهنمای کوتاه تحلیل و استفاده از دادههای دستورکارها (Work Order Data Guide) توصیه میشود.
تحلیل علل ریشهای (Root Cause Analysis – RCA)
تحلیل علل ریشهای (RCA) صرفاً یک ابزار رفع اشکال (Troubleshooting Tool) نیست، بلکه ابزاری برای استخراج ارزش پایدار از فرایند رفع اشکال به شمار میآید. یک یاتاقان ناهمراستا (Misaligned Bearing) ممکن است بدون اجرای RCA تعمیر شود، اما در این صورت احتمال تکرار چندباره همان خرابی وجود دارد. این تکرار منجر به صرف مکرر زمان (Time)، بودجه (Budget) و قطعات (Parts) خواهد شد.
ارزش واقعی FRACAS زمانی محقق میشود که منجر به بهبودهای پایدار (Long-lasting Improvements) گردد؛ بهبودهایی که کاهش هزینهها و بازگرداندن زمان به برنامههای تولید را تضمین کنند. این همان هدفی است که RCA برای تحقق آن طراحی شده است.
در این مقاله به جزئیات فنی اجرای RCA پرداخته نمیشود؛ چراکه قالبهای استاندارد و راهنماهای آن از پیش تدوین شدهاند. با این حال، نمونهای از ادغام RCA در چرخه FRACAS را میتوان از طریق مثال یاتاقان ناهمراستا نشان داد:
چرا یاتاقان ناهمراستا شد؟ چون شفت ناهمراستا بود.
چرا شفت ناهمراستا بود؟ چون ماشین بهصورت نادرست مونتاژ شده بود.
چرا ماشین نادرست مونتاژ شد؟ چون تکنسین در فرآیند مونتاژ عجله کرده بود.
چرا تکنسین عجله کرد؟ چون زمان کافی برای انجام کار در اختیار او قرار داده نشده بود.
چرا زمان کافی اختصاص نیافت؟ چون بازه زمانی نگهداری روتین پیش از آغاز تولید بسیار کوتاه بود.
این زنجیره پرسشها نشان میدهد که خرابی ناشی از یک عامل ساده نیست، بلکه نتیجه مجموعهای از شرایط و تصمیمات است.
مهمترین نکته در اجرای RCA پرهیز از نتیجهگیری شتابزده و توقف زودهنگام بررسیهاست. همانگونه که Thibaut Drevet تأکید میکند:
«بسیار آسان است که فرض شود یک علت ساده، دلیل اصلی خرابی دارایی است. به همین دلیل، مشارکت افراد با تخصصها و دیدگاههای متنوع در RCA ضروری است تا زوایای مختلف موضوع بررسی شود و از شکلگیری فرضیات نادرست جلوگیری گردد.»
تعدیل راهبرد (Strategy Adjustment)
تمامی بینشهای حاصل از چرخه FRACAS (FRACAS Loop) زمانی ارزشمند خواهند بود که به اقدام عملی (Action) منجر شوند. اقدام لزوماً به معنای ایجاد تغییرات بزرگ نیست؛ گاهی میتواند در قالب اصلاحات سادهای همچون افزودن دستورالعمل دقیقتر برای روانکاری در یک دستورکار (Work Order) نمود پیدا کند. بااینحال، در برخی شرایط، اتخاذ تغییرات اساسی ضرورت مییابد؛ برای مثال، استفاده از پیمانکاران برای انجام وظایف تخصصی که تیم داخلی آموزش لازم برای آنها را ندارد.
اگرچه واکنشها باید متناسب با هر موقعیت طراحی شوند، اما چند راهبرد رایج میتواند در اصلاح فرآیندها و پیشگیری از خرابیها در بلندمدت مؤثر واقع شود:
مشارکت تکنسینها در فرآیند: در بسیاری موارد، تکنسینها راهحلهایی ارائه میدهند که پیشتر مورد توجه قرار نگرفتهاند. توضیح شفاف درباره دلایل تغییر و منافع حاصل از آن، سطح پذیرش تغییر (Buy-in) را افزایش میدهد. همچنین لازم است نتایج تغییرات با آنان به اشتراک گذاشته شود. برای نمونه، اگر یک فرآیند اصلاحشده منجر به کاهش ۴۰ درصدی تماسهای خارج از ساعت کاری گردد، اعلام آن علاوه بر قدردانی از تلاش کارکنان، زمینهساز پذیرش تغییرات آتی خواهد بود.
پایش نتایج (Monitor Outcomes): در صورتی که یک راهبرد بازدهی مورد انتظار را نداشته باشد، شناسایی سریع آن امکان اصلاح مجدد را فراهم میکند. باید به اثر دومینو (Domino Effect) توجه داشت؛ چراکه تغییر مثبت در یک بخش میتواند پیامدهای منفی در بخش دیگر به همراه داشته باشد. ثبت و مستندسازی داستانهای موفقیت نیز اهمیت دارد، زیرا در آینده برای جلب حمایت و تأمین بودجه از مدیران مورد استفاده قرار خواهد گرفت.
شروع کوچک و گسترش تدریجی (Start Small and Expand Slowly): در صورت ضرورت تغییرات بزرگ، اجرای همزمان آنها توصیه نمیشود. تمرکز بر یک بخش کوچک از تغییرات، فرآیند پیادهسازی را سادهتر میسازد و به کارکنان فرصت میدهد تا با شرایط جدید سازگار شوند. بهعنوان نمونه، اگر تصمیم بر افزایش زمان در دسترس برای فعالیتهای نگهداری حتی به بهای کاهش تولید باشد، آغاز این تغییر از یک تجهیز بهتنهایی بهترین رویکرد خواهد بود.
بهکارگیری این رویکردها تضمین میکند که اصلاحات نهتنها پایدار باقی بمانند، بلکه به بهبود مستمر در عملکرد نگهداری و قابلیت اطمینان داراییها منجر شوند.
بستن چرخه (Closing the Loop)
پس از اجرای تعدیل راهبرد (Strategy Adjustment)، چرخه FRACAS (FRACAS Loop) مجدداً آغاز میشود. تکمیل این چرخه و استمرار در شناسایی و اصلاح خرابیها مستلزم آن است که نتایج اقدامات انجامشده بهطور نظاممند بازتاب یافته و در فرآیندها ادغام گردد. برای این منظور، سه فعالیت کلیدی توصیه میشود:
بهروزرسانی FMEA (Failure Modes and Effects Analysis): تغییرات ایجادشده باید در سند FMEA منعکس شوند؛ چه در قالب شناسایی خرابیهای جدید و چه از طریق ثبت اثرات تغییرات انجامشده. برای مثال، ممکن است فراوانی وقوع یک خرابی کاهش یابد یا یک روش جدید برای مدیریت نوع خاصی از خرابی بهواسطه اجرای FRACAS تعریف شود.
بازبینی کدهای خرابی (Failure Codes Audit): کدهای جدید و پرکاربرد باید به فهرست اضافه شوند و کدهایی که بهندرت مورد استفاده قرار میگیرند حذف گردند. این بازبینی تضمین میکند که کدهای موجود همچنان مرتبط، شفاف و قابلکاربرد باقی بمانند.
ایجاد گزارشها (Reporting): تهیه گزارشهای تحلیلی ضروری است تا تأثیر تغییرات بهصورت کمی و کیفی پایش شود. این گزارشها باید به پرسشهایی کلیدی پاسخ دهند؛ از جمله اینکه آیا میزان خرابی در حوزههایی که اقدامات اصلاحی در آنها انجام شده کاهش یافته است؟ و این تغییرات چه اثری بر هزینهها (Costs)، زمانبندی (Scheduling) و سایر شاخصهای کلیدی عملکرد داشتهاند؟
بدین ترتیب، چرخه FRACAS بهطور پیوسته تکمیل و بازآغاز میشود و سازمان قادر خواهد بود از یک فرآیند یادگیری مستمر برای بهبود قابلیت اطمینان داراییها و افزایش بهرهوری بهرهبرداری کند.
چگونه دادههای باکیفیت برای FRACAS به دست آوریم
داده (Data) نقش راهنما را در تمامی مراحل سیستم FRACAS (Failure Reporting, Analysis, and Corrective Action System) ایفا میکند. همانند هر راهنمای معتبر، این دادهها باید قابل اعتماد (Trustworthy) باشند؛ امری که همواره تضمینشده نیست. هرچند دستیابی به دادهای صددرصد بینقص امکانپذیر نیست، اما با اتخاذ اقدامات کلیدی میتوان کیفیت اطلاعات را به شکل چشمگیری ارتقا داد.
یکی از مهمترین این اقدامات، ایجاد فرهنگی است که ارزش نگهداری در آن درک شود. بخش قابل توجهی از خطاهای دادهای زمانی رخ میدهد که تکنسینها تحت فشار شدید زمان قرار دارند. همانگونه که Thibaut Drevet اشاره میکند، تکنسینها غالباً حتی فرصت کافی برای تکمیل یک کار را ندارند و ناچارند بلافاصله به وظیفه بعدی بپردازند. در چنین شرایطی، برای جلوگیری از بروز نارضایتی در بخش تولید، ثبت دادهها به پایان روز موکول میشود؛ زمانی که حافظه و دقت کاهش یافته است. در برخی موارد نیز دادهها اساساً ثبت نمیشوند.
وجود یک فرهنگ سازمانی سالم (Healthy Culture) که در آن تمامی افراد ارزش نگهداری را درک کنند، میتواند این مشکل را برطرف سازد. به بیان Thibaut:
«همه باید بدانند که نگهداری دشمن تولید نیست. زمانی که این درک شکل گیرد که نگهداری اقدامی ضروری و سودمند است، تکنسینها فرصت و انگیزه کافی خواهند داشت تا دادهها را بهدرستی ثبت کنند.»
ساخت دستورکارهای شفاف و ساده برای تکمیل (Build Clear, Easy-to-Fill Work Orders)
کیفیت پایین دادهها اغلب به خطای انسانی (Human Error) نسبت داده میشود، اما این خطاها معمولاً ریشههای عمیقتری دارند. یکی از رایجترین عوامل، استفاده از دستورکارهای نامفهوم و پیچیده (Unclear, Overwhelming Work Orders) است که موجب افزایش احتمال اشتباه در ثبت و تفسیر اطلاعات میگردد.
برای نمونه، در غیاب تصاویر (Pictures)، نمودارها (Diagrams) یا رویههای استاندارد نامگذاری (Naming Conventions)، شناسایی یک قطعه ممکن است بهسادگی با خطا همراه شود. چنین خطایی میتواند فرآیند تحلیل و گزارشهای خرابی آتی را برای همان دارایی یا داراییهای مشابه مخدوش نماید. علاوه بر این، در صورت فقدان فرآیند مشخص برای گزارشدهی و پیگیری خرابیها، احتمال زیادی وجود دارد که هیچ اقدام اصلاحی صورت نگیرد.
بنابراین، طراحی دستورکارهایی که شفاف، ساده و استاندارد باشند، نقشی اساسی در ارتقای کیفیت دادهها و بهبود کارایی چرخه FRACAS ایفا میکند.
خودکارسازی و یکپارچهسازی (Automate and Integrate)
ایجاد دستورکارهای دقیق و استاندارد میتواند احتمال خطاهای انسانی را کاهش دهد، اما این خطاها هرگز بهطور کامل حذف نخواهند شد. از آنجا که خطای انسانی همواره محتمل است، بهرهگیری از فناوری میتواند این ریسک را به میزان قابل توجهی کاهش دهد. بهویژه، استفاده از نرمافزارهای مانیتورینگ وضعیت (Condition-Monitoring Software) بر روی تجهیزات، ورود دستی دادهها را با اندازهگیریهای خودکار جایگزین میسازد.
برای نمونه، ثبت دستی یک عدد کنتور (Meter Reading) در تجهیزی که دچار خرابی شده است میتواند بهراحتی منجر به خطا گردد. ممکن است چند دقیقه طول بکشد تا فرد به دستگاه برسد و در این فاصله، مقدار کنتور تغییر کرده باشد. در نتیجه، خرابی با دادهای نادرست ثبت میشود. در مقابل، استفاده از نرمافزاری که قرائتهای کنتور را بهصورت همزمان (Real-time) ثبت میکند، این ریسک را حذف خواهد کرد. چنین سیستمی قادر است دقیقاً همان عدد مربوط به لحظه وقوع خرابی را ذخیره کرده و از صحت دادهها اطمینان حاصل نماید.
افزون بر این، یکپارچهسازی (Integration) چنین سامانههایی با نرمافزارهای نگهداری (Maintenance Software) امکان گردآوری و تحلیل تمامی اطلاعات در یک بستر واحد را فراهم میسازد. مزیت دیگر این رویکرد آن است که فعالیتهای نگهداری میتوانند بلافاصله و بهطور خودکار بر اساس دادههای کنتور فعال شوند؛ عاملی که به ارتقای دقت، سرعت و کارایی فرآیند نگهداری منجر میشود.
بازبینی مداوم دادهها (Audit Your Data Frequently)
اختصاص زمان مشخص بهصورت ماهانه برای بازبینی دادهها اقدامی ضروری است تا اطمینان حاصل شود اطلاعات ثبتشده دقیق و معتبر باقی ماندهاند. این فرایند به معنای مرور و تأیید تکتک دستورکارها و دادهها نیست؛ بلکه از طریق نمونهبرداری (Spot Checks)، جستوجوی نشانههای هشداردهنده (Red Flags) و گفتوگو با تکنسینها میتوان اطمینان یافت که دادهها واقعی و قابل اتکا هستند. یکی از موضوعات کلیدی در این بازبینی، بررسی احتمال وقوع Pencil Whipping (ثبت صوری دادهها بدون اجرای واقعی فعالیتها) است.
در این مسیر باید از سرزنش مستقیم (Finger Pointing) پرهیز شود، زیرا Pencil Whipping اغلب ناشی از موانع سیستمی و فشارهای بیرونی است، نه ضعف شخصیتی یا مهارتی تکنسینها.
چند پرسش کلیدی که در فرآیند بازبینی دادهها میتواند راهگشا باشد عبارتاند از:
آیا بازبینی یا فعالیتی غیرضروری به نظر میرسد؟ در این حالت، آن فعالیت باید حذف، بسامد آن کاهش یا دلیل اهمیت آن بهروشنی توضیح داده شود.
آیا مشخص است چه دادهای باید ثبت شود و چرا اهمیت دارد؟ ضروری است همه کارکنان درک مشترکی از نوع داده موردنیاز و شیوه صحیح ثبت آن داشته باشند. بهعنوان مثال، اگر شاخص زمانی ثبت میشود، باید بهصورت دقیق برحسب دقیقه درج گردد، نه ساعت.
آیا فرآیند ثبت دادهها ساده است؟ در غیر این صورت، باید دلایل پیچیدگی شناسایی شود. برخی فرآیندها ممکن است در تئوری منطقی باشند، اما در عمل قابل استفاده نباشند؛ مانند فهرستهای طولانی کدهای خرابی یا شاخصهایی که بهسختی قابل کمیسازی هستند.
بازبینی مداوم دادهها نهتنها موجب ارتقای دقت اطلاعات میشود، بلکه اعتماد به نتایج چرخه FRACAS را افزایش داده و از ایجاد روندهای تصمیمگیری بر پایه دادههای مخدوش جلوگیری میکند.
چگونه از FRACAS استفاده کنیم: پنج گزارش کلیدی برای دستیابی به نتایج بهتر
شناسایی و اصلاح خرابیها ارزشمند است؛ اما تمرکز بر خرابیهایی که مانع افزایش تولید و سودآوری سازمان میشوند، اهمیت بیشتری دارد. برای دستیابی به چنین بینشی، گزارشهایی مورد نیاز است که توانایی شناسایی این دسته از خرابیها را داشته باشند. در ادامه، پنج گزارش کلیدی معرفی میشود که میتوانند نقطه آغاز مناسبی برای بهرهگیری مؤثر از FRACAS باشند:
خرابیهای پس از راهاندازی (Failures After Start-up):
خرابیهایی که پیش از شروع تولید رخ میدهند، تأخیرهای قابل توجهی در عملیات ایجاد میکنند. این گزارش به شناسایی این نوع خرابیهای زیانبار و طراحی اقداماتی برای جلوگیری از تکرار آنها کمک میکند.هزینههای نگهداری بر اساس کد خرابی (Maintenance Costs by Failure Code):
در این گزارش، مجموع هزینه نیروی کار و قطعات در دستورکارهای بستهشده بر مبنای کدهای خرابی محاسبه میشود. نتایج بهدستآمده نشان میدهد کدام خرابیها بیشترین هزینه را ایجاد کردهاند و باید در اولویت اصلاح قرار گیرند.ساعتهای نگهداری بر اساس کد خرابی (Maintenance Hours by Failure Code):
صرف زمان مکرر برای رفع یک خرابی مشابه موجب میشود منابع از انجام فعالیتهایی بازبمانند که میتوانند مانع وقوع توقفهای دیگر شوند. این گزارش دیدگاه روشنی درباره توزیع ساعات نگهداری فراهم میآورد.خرابیهای شناساییشده در نگهداری زمانبندیشده در مقایسه با نگهداری اضطراری (Failures Found Through Scheduled vs. Unscheduled Maintenance):
این گزارش کمک میکند خرابیهای تکرارشوندهای شناسایی و اولویتبندی شوند که منجر به نگهداری واکنشی پرهزینه (Reactive Maintenance) میگردند.خرابیها بر اساس شیفت یا سایت (Failures by Shift or Site):
این گزارش مشکلات عمدهای را آشکار میسازد که ریشه در فرآیندها یا آموزش دارند. اصلاح این موارد میتواند به دستاوردهای قابل توجهی منجر شود. همچنین، در صورتی که یک شیفت یا سایت نرخ خرابی پایینتری داشته باشد، میتوان اقدامات متفاوت آنها را بررسی و در سایر بخشها تکرار کرد.
بهکارگیری این گزارشها نهتنها امکان شناسایی دقیقتر الگوهای خرابی را فراهم میکند، بلکه سازمان را در جهت استفاده بهینه از چرخه FRACAS و دستیابی به بهبودهای پایدار یاری میدهد.
چگونه از FRACAS استفاده کنیم: نمونههای واقعی و کاربردها برای کسبوکار
یکی از چالشهای اصلی در استقرار FRACAS (Failure Reporting, Analysis, and Corrective Action System) این است که این سامانه بهراحتی میتواند به یک فایل دیگر در رایانه تبدیل شود، بدون آنکه نقشی واقعی در بهبود ایفا کند. دلیل این موضوع آن است که FRACAS نیازمند تغییر در شیوه کار تیم نگهداری است و این تغییر اغلب آسان نیست. با این حال، درک دقیق مشکلاتی که FRACAS قادر به حل آنهاست، میتواند دشواریهای این گذار را کاهش دهد. در ادامه، چند نمونه واقعی از کاربردهای FRACAS ارائه میشود که نشان میدهد این سیستم چگونه میتواند برخی از بزرگترین چالشهای تیم نگهداری را هدف قرار دهد:
بهبود مدیریت موجودی قطعات (Spare Parts Inventory):
تحلیل FRACAS نشان میدهد که تجهیزات بیشترین میزان خرابی را در زمان استفاده از قطعات قدیمی (Old Parts) برای تعمیر یا تعویض تجربه میکنند. دادهها همچنین نشان میدهند این خرابیها چه میزان هزینه نگهداری (Maintenance Cost) و تولید ازدسترفته (Lost Production) ایجاد کردهاند. این شواهد امکان توجیه درخواست افزایش بودجه موجودی را فراهم میکند تا این دسته از خرابیها حذف شوند.پاسخ به تغییرات مشخصات تولید (Product Specifications):
یک دارایی که پیشتر بهندرت دچار خرابی میشد، بهطور ناگهانی با افزایش خرابیها مواجه شده است. تحلیل FRACAS مشخص میسازد که این خرابیها به یک جزء (Component) خاص مربوط هستند و از زمانی آغاز شدهاند که خط تولید از مشخصات جدید محصول (Product Specs) استفاده کرده است. از آنجا که تیم نگهداری در جریان این تغییر قرار نگرفته بود، تنظیمات ماشین بهدرستی انجام نشد. در واکنش به این موضوع، یک فرآیند جدید برای اطلاعرسانی تغییرات خط تولید طراحی میشود که موجب کاهش توقفات (Downtime) در چندین سایت میگردد.اولویتبندی منابع بر اساس تحلیل ریسک:
بازبینی کدهای خرابی سه نوع خرابی رایج را آشکار میکند، اما منابع موجود تنها برای رسیدگی به یکی از آنها در این دوره سهماهه کافی است. با استفاده از FMEA (Failure Modes and Effects Analysis)، گزارشهای هزینه و تحلیل علل ریشهای (RCA)، خرابی با بیشترین اثر (Biggest Impact) انتخاب میشود. پس از موفقیت در مدیریت این خرابی، سازمان میتواند بودجه لازم برای جذب تکنسینهای بیشتر (Technicians) و رسیدگی به سایر خرابیهای شناساییشده را به دست آورد.
این نمونهها نشان میدهند که FRACAS تنها ابزاری برای ثبت خرابیها نیست، بلکه چارچوبی استراتژیک برای تصمیمگیری، بهینهسازی منابع و دستیابی به بهبودهای پایدار در عملکرد نگهداری و بهرهوری سازمان به شمار میآید.
نتیجهگیری
ایجاد یک سیستم گزارشدهی، تحلیل و اقدام اصلاحی خرابی (FRACAS – Failure Reporting, Analysis, and Corrective Action System) بر سه عنصر اساسی استوار است: داده (Data)، زمان (Time) و تعهد (Commitment).
برای شناسایی و رفع علت ریشهای (Root Cause) خرابیها، وجود دادههای کافی و باکیفیت ضرورت دارد. جمعآوری این دادهها مستلزم صرف زمان است و دستیابی به موفقیت پایدار تنها در صورت تعهد بلندمدت به ثبت دقیق اطلاعات و بهرهگیری عملی از درسآموختهها امکانپذیر خواهد بود.
تسلط بر این عناصر نیازمند زمان است؛ از اینرو، توصیه میشود فرآیند با گامهای کوچک آغاز شود (Start Small). ثبت و پیگیری موفقیتها (Track Your Wins) نقش مهمی در استمرار انگیزه دارد و در صورت عدم مشاهده نتایج فوری، نباید ناامیدی به وجود آید.
این تلاش در نهایت ارزشمند خواهد بود، زیرا بازگشت سرمایه بلندمدت (Long-term ROI) ناشی از اجرای صحیح FRACAS، قابل توجه و اثرگذار بر بهرهوری و سودآوری سازمان است.
https://fiixsoftware.com/blog/what-is-fracas/ :FRACAS: How to make equipment failure your friend
Powered by Froala Editor

.jpg)

برای ثبت نظر ابتدا وارد حساب کاربری خود شوید