

چگونه میتوان از چرخه نگهداری واکنشی (Reactive Maintenance) عبور کرد؟
رهایی از چرخه معیوب نگهداری واکنشی
بسیاری از سازمانها با چالش مداوم نگهداری واکنشی (Reactive Maintenance) روبهرو هستند و بهدنبال راهی برای خروج از این وضعیتاند. این مشکل، که بهعنوان «چرخه معیوب تعمیرات اضطراری» شناخته میشود، بهصورت گسترده در صنایع مشاهده میگردد. در چنین شرایطی، بهمحض برطرف شدن یک خرابی اضطراری، خرابیهای متعددی (گاه بیش از ۱۰ مورد) بهطور همزمان رخ میدهند که نیازمند رسیدگی فوری هستند. ازآنجاکه این موارد ماهیت اضطراری دارند، هیچ فرصتی برای برنامهریزی، زمانبندی دقیق یا آمادهسازی قطعات و ابزارها (Staging & Kitting) باقی نمیماند.
این روند یک چرخه بیپایان ایجاد میکند که موجب تأخیرهای متوالی، کمبود منابع و اتلاف وقت در تیمهای نگهداری میشود و مانع خروج سازمان از نگهداری واکنشی خواهد شد. چنین وضعیتی نهتنها باعث کاهش بهرهوری میشود، بلکه فشار روانی و نارضایتی کارکنان را نیز بهشدت افزایش میدهد؛ بهطوریکه همواره این احساس وجود دارد که زمان، انرژی و منابع کافی برای غلبه بر این چرخه وجود ندارد.
به همین دلیل، در این مقاله سه رویکرد کلیدی معرفی میشود که پیادهسازی آنها میتواند به شکستن این چرخه معیوب و ایجاد فضای کافی برای انجام بهبودهای راهبردی و وظایف مهمتر منجر شود.
چرخه معیوب (The Vicious Cycle) در نگهداری واکنشی (Reactive Maintenance)
این چرخه بهدرستی «چرخه» نامیده میشود، زیرا بهمحض گرفتار شدن در آن، رهایی بدون حمایت و تغییرات اساسی تقریباً غیرممکن است. در این رویکرد، تعمیرات همواره پس از وقوع خرابیها انجام میگیرند که این امر بهمراتب پرهزینهتر از نگهداری برنامهریزیشده و زمانبندیشده است. روند معمول این چرخه بهصورت زیر اتفاق میافتد:
رخدادهای پیدرپی خرابی: هر بار که یک خرابی رخ میدهد، تیم نگهداری که از قبل تحت فشار کاری شدید قرار دارد، با وظایف بیشتری مواجه میشود.
تعمیرات موقت و ناکارآمد: برای تسریع در کار، تعمیرات موقتی انجام میشود که دوام چندانی ندارند و در نهایت باعث افزایش حجم کار و تکرار خرابیها میشوند.
افزایش هزینه و کاهش منابع: افزایش هزینههای ناشی از این روند، منجر به فشار بیشتر بر بودجه و نیروی انسانی شده و در نهایت محدودیت یا کاهش منابع در تیم نگهداری رخ میدهد.
افزایش عقبماندگی و افت کیفیت: با نیروی کمتر و حجم کار بیشتر، عقبماندگی کارها (Backlog) بهطور مداوم افزایش مییابد، کیفیت کار کاهش پیدا میکند و روحیه تیم بهشدت افت میکند.
تعطیلی برنامههای نگهداری پیشگیرانه: اجرای نگهداری پیشگیرانه (Preventive Maintenance - PM) متوقف یا ناقص میشود، زیرا زمان کافی برای انجام آن وجود ندارد. این امر منجر به خرابیهای بیشتر و بازگشت به نقطه آغاز چرخه واکنشی میگردد.
این چرخه، فرآیندی فرساینده و روحیهکُش است که نهتنها بهرهوری سازمان را مختل میکند بلکه تیمهای عملیاتی را درگیر استرس و اضطراب شدید میسازد. بااینحال، راه خروج وجود دارد: میتوان با اتخاذ راهبردهای صحیح از این چرخه رهایی یافت. بر اساس تجارب عملی، دو گام کلیدی برای شکستن این چرخه معرفی میشود که زمینه بازگشت کنترل و افزایش قابلیت اطمینان تجهیزات را فراهم میسازد.
گام ۱: اولویتبندی کارها از طریق برنامهریزی و زمانبندی (Planning & Scheduling)
برای خروج از چرخه نگهداری واکنشی، اولویتبندی عینی (Objective Prioritisation) یک ضرورت اساسی است. تعیین درست اولویتها برای درخواستهای کاری جدید موجب میشود برنامه هفتگی تیم نگهداری از بینظمی محافظت شود، فرصت کافی برای برنامهریزی و زمانبندی دقیق فراهم گردد و میزان وقفهها و اختلالات کاری بهطور قابلتوجهی کاهش یابد.
لازم است از اولویتدهی احساسی یا سلیقهای اجتناب شود؛ بهعنوان مثال، کار فردی که صرفاً اصرار دارد وظیفهاش «اولویت اصلی» است یا بلندتر اعتراض میکند، نباید بدون ارزیابی صحیح در صدر اولویتها قرار گیرد.
برای دستیابی به این هدف، استفاده از روشهای استاندارد و مبتنی بر داده توصیه میشود. یکی از ابزارهای کاربردی در این زمینه، شاخص رتبهبندی هزینههای نگهداری (Ranking Index for Maintenance Expenditure – RIME) است.
شاخص RIME بهعنوان یک روش اولویتبندی، از ماتریسی بهره میگیرد که سطح بحرانی بودن تجهیزات (Equipment Criticality) و انواع فعالیتهای نگهداری (Maintenance Work Types) را ترکیب میکند. این روش امکان میدهد که وظایف نگهداری نه براساس قضاوت فردی، بلکه بر اساس دادهها و اهمیت واقعی هر دارایی تعیین اولویت شوند.
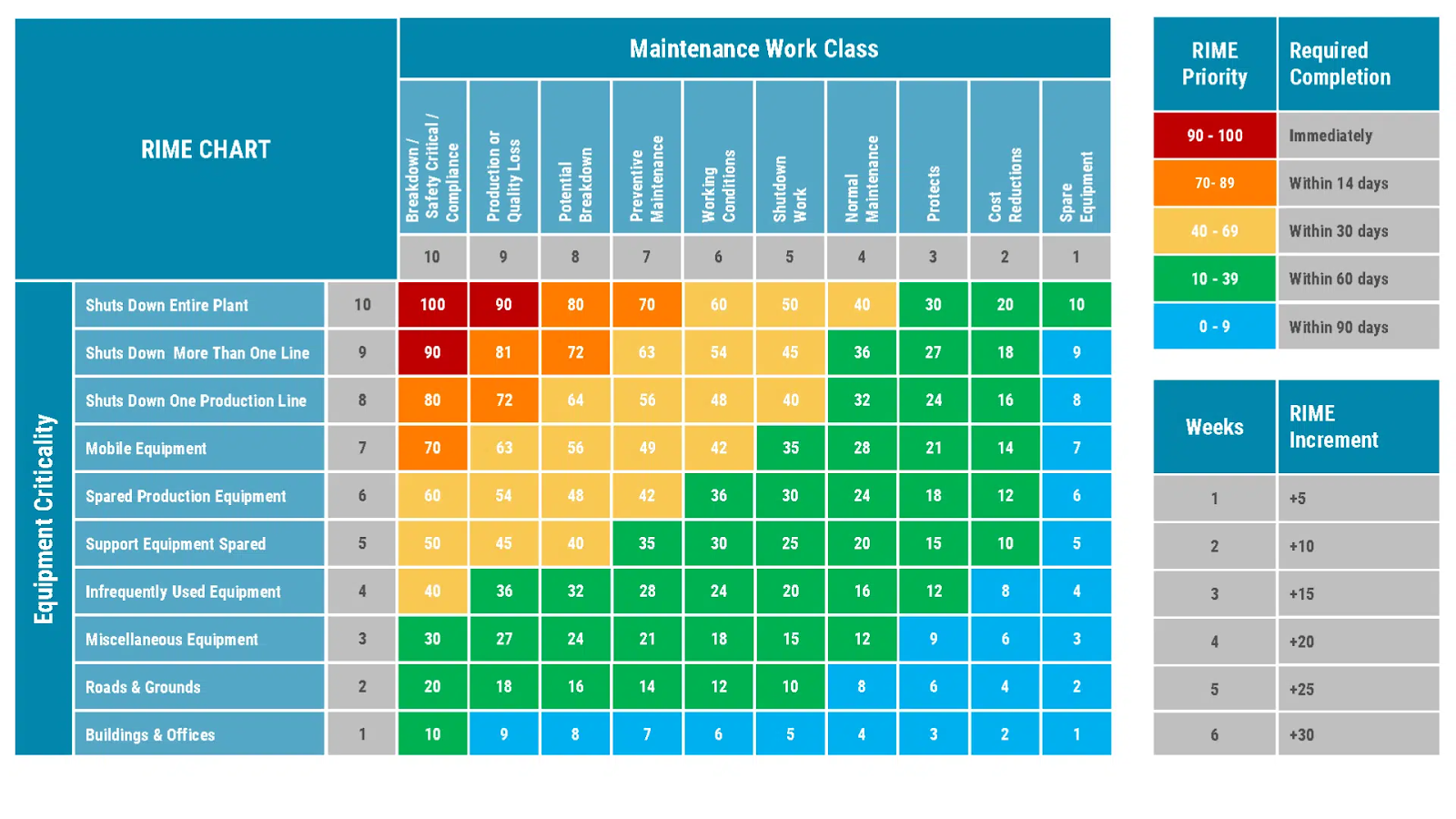
ماتریس اولویتبندی RIME (Ranking Index for Maintenance Expenditure)
در ماتریس (Matrix)، ردیفها نشاندهنده سطح بحرانی بودن تجهیزات (Equipment Criticality) هستند که از تجهیزات فوقبحرانی، مانند خرابیهایی که باعث توقف کامل خط تولید یا کارخانه میشوند، تا تجهیزات کماهمیتتر (نظیر تجهیزات رزرو یا ساختمانها) را دربر میگیرند. ستونها نمایانگر طبقهبندی فعالیتهای نگهداری (Maintenance Work Classes) هستند که از وظایف حیاتی مرتبط با ایمنی تا فعالیتهای با اولویت پایینتر را شامل میشوند.
برای هر ردیف و ستون، یک عدد بین ۱۰ (بالاترین اولویت) تا ۱ (کمترین اولویت) اختصاص داده میشود. امتیاز اولویت (Prioritisation Score) از طریق ضرب این مقادیر محاسبه میگردد. با توجه به تکرار مقادیر، در یک ماتریس ۱۰×۱۰ تعداد نتایج متمایز کمتر از ۱۰۰ حالت خواهد بود.
برای سادهسازی و سهولت در استفاده، این ماتریس از کدگذاری رنگی (Color-Coding) بهره میبرد که امتیازات اولویت را در پنج گروه اصلی دستهبندی میکند. هر گروه دارای تاریخ هدف تکمیل (Target Completion Date) مشخصی است؛ بهطوریکه کارهای اضطراری نیازمند اقدام فوری بوده و فعالیتهای کماهمیتتر میتوانند در بازههای زمانی طولانیتری انجام شوند.
همچنین، عدد RIME میتواند با گذشت زمان افزایش یابد تا اولویت کارهایی که مدت طولانیتری در لیست باقی ماندهاند، بالاتر برود. این روش، رویکردی دقیقتر، مؤثرتر و ساختاریافتهتر نسبت به مقیاسهای ساده «بالا–متوسط–پایین» یا «۱ تا ۵» ارائه میدهد و قابلیت سفارشیسازی بر اساس نیازهای خاص هر سازمان را داراست.
ماتریس ارزیابی ریسک (Risk Assessment Matrix – RAM)
ماتریس ارزیابی ریسک (RAM) مشابه شاخص RIME از ساختار ماتریسی (Matrix) استفاده میکند، اما تمرکز اصلی آن بر ارزیابی ریسک (Risk Assessment) قرار دارد. این ماتریس ابزاری کارآمد برای شناسایی و دستهبندی ریسکها بر اساس احتمال وقوع و شدت پیامدهاست.
در RAM دو محور متقاطع تعریف شده است:
محور احتمال وقوع (Likelihood): این محور بیانگر میزان احتمال رخداد یک رویداد است که از سطح پایین به سطح بالا افزایش مییابد.
محور شدت پیامدها (Severity): این محور شدت یا تأثیر پیامدهای ناشی از یک رویداد را نشان میدهد که از کمخطر تا شرایط بحرانی تغییر میکند.
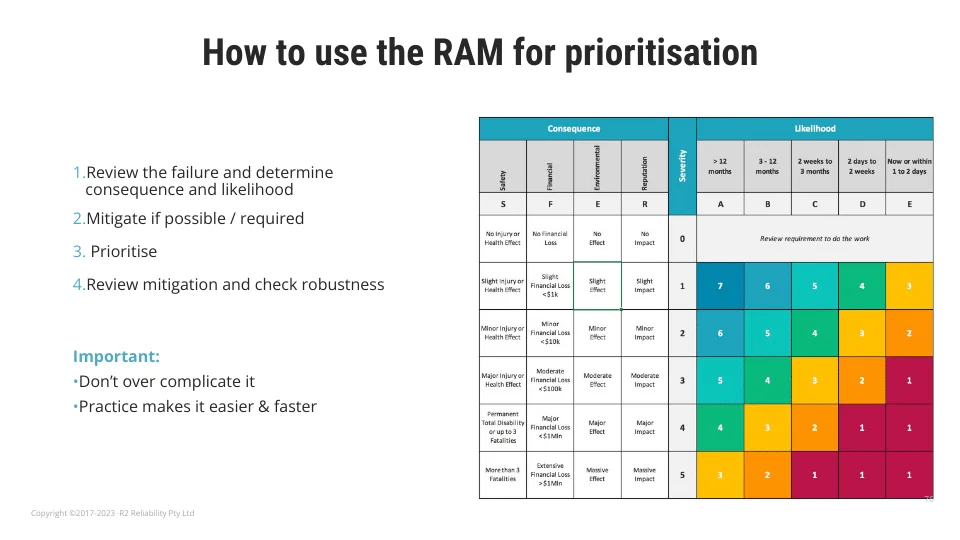
کاربرد ماتریس ارزیابی ریسک (Risk Assessment Matrix – RAM)
در این ماتریس (Matrix)، پروفایلهای مختلف ریسک بهصورت ساختاریافته شناسایی میشوند. خانه بالا-چپ نشاندهنده رویدادهایی با احتمال وقوع کم (Low Likelihood) و شدت پایین (Low Severity) است که معمولاً در گروه ریسک پایین (Low Risk) قرار میگیرند. در مقابل، خانه پایین-راست بحرانیترین ناحیه ماتریس محسوب میشود، زیرا احتمال وقوع بالا (High Likelihood) و شدت بالا (High Severity) را همزمان ترکیب کرده و معرف سناریوهای پرریسک (High-Risk Scenarios) است.
در نتیجه، سطح ریسک و اولویت از بالا-چپ به سمت پایین-راست ماتریس بهصورت تصاعدی افزایش مییابد؛ بهگونهای که ریسکهای پایین با اولویت پایین و ریسکهای بالا با اولویت بالا همراستا هستند.
بهمنظور افزایش کارایی RAM، این ماتریس معمولاً به پنج ستون و پنج ردیف تقسیم میشود. اما برخلاف شاخص RIME که در آن ستونها و ردیفها برای بهدست آوردن امتیاز (Score) در هم ضرب میشوند، در ماتریس ریسک، گروهبندیها بهصورت سطحبندی انجام میشود تا فرایند اولویتبندی سادهتر و شفافتر گردد.
دستهبندی محورها:
محور احتمال وقوع (Likelihood): از ستون A تا E درجهبندی میشود.
محور شدت پیامدها (Severity): از ۰ تا ۵ سطحبندی دارد.
دستهبندی پیامدها (Consequence Categories): شامل حوزههایی همچون ایمنی (Safety)، مالی (Financial)، زیستمحیطی (Environmental) و اعتبار (Reputation) است که برای تحلیل دقیقتر اثرات ریسک بهکار گرفته میشوند.
گام ۲: حذف خرابیهای تکراری از طریق حذف عیوب (Defect Elimination)
پس از استقرار یک فرایند برنامهریزی و زمانبندی (Planning & Scheduling) که سفارشهای کاری را بهصورت مؤثر و اصولی اولویتبندی میکند، گام بعدی تمرکز بر حذف عیوب و نواقصی است که منشأ خرابیهای تکراری محسوب میشوند. واقعیت این است که بیشتر خرابیهای موجود در واحدهای صنعتی پیشتر نیز رخ دادهاند و معمولاً راهکارهایی برای جلوگیری از تکرار آنها وجود دارد. در این رویکرد بهجای رفع مکرر خرابیها، هدف رفع دائمی علت اصلی است.
این پرسش مطرح میشود که: «وقتی تحلیل علل ریشهای (Root Cause Analysis – RCA) انجام میشود، چه نیازی به حذف عیوب (Defect Elimination) وجود دارد؟» در پاسخ باید گفت، گرچه هدف RCA نیز پیشگیری از تکرار خرابیهاست، اما تمرکز آن عمدتاً بر خرابیهای بزرگ و پرهزینه است. در مقابل، عیبها و مشکلات کوچکتر، اگرچه ممکن است در ابتدا کماهمیت به نظر برسند، اما در صورت بیتوجهی میتوانند به بحرانهای جدی با پیامدهای سنگین تبدیل شوند.
در چنین شرایطی، حذف عیوب (Defect Elimination) بهعنوان یک راهبرد مکمل وارد عمل میشود و امکان میدهد تا تیمهای عملیاتی و پشتیبانی بهطور مستقل عیوب کوچک اما تکرارشونده را شناسایی و اصلاح کنند. اجرای صحیح این رویکرد نهتنها موجب افزایش قابلیت اطمینان (Reliability) تجهیزات میشود، بلکه فرهنگ قابلیت اطمینان را در سطح سازمان تقویت کرده و مشارکت فعال تمام بخشها را در بهبود عملکرد داراییها تضمین میکند. در نهایت، قابلیت اطمینان همانند ایمنی، به یک مسئولیت مشترک و فراگیر سازمانی تبدیل میشود.
گام ۳: بهینهسازی برنامه نگهداری پیشگیرانه (Preventive Maintenance Program)
بسیاری از برنامههای نگهداری پیشگیرانه (PM Program) از ابتدا بهطور صحیح طراحی نشدهاند و در نتیجه اثربخشی لازم را ندارند. همانگونه که جان موبری (John Moubray)، بنیانگذار RCM II (Reliability-Centered Maintenance II)، در کتاب خود تأکید کرده است، بین ۴۰ تا ۶۰ درصد وظایف PM در اغلب برنامههای نگهداری پیشگیرانه ارزش واقعی ایجاد نمیکنند.
برخی از مشکلات رایج در این برنامهها عبارتاند از:
وجود وظایف تکراری که موجب اتلاف منابع میشوند.
اجرای وظایف با تناوبهای نامناسب؛ یا بیش از حد انجام میشوند یا بسیار کمتکرار هستند.
وظایفی که تناسب کافی با حالت خرابی (Failure Mode) ندارند و در کاهش ریسک خرابی مؤثر نیستند.
تمرکز بر وظایف با زمانبندی ثابت و تعمیرات تهاجمی (Fixed-Time Intrusive Overhaul Tasks) که میتوانند در صورت اجرای نگهداری مبتنی بر وضعیت (Condition-Based Maintenance) هم اثربخشتر، هم کمهزینهتر و هم کماختلالتر باشند.
عدم استفاده از دادههای خرابی و تجربیات گذشته برای تعیین تناوب بهینه وظایف.
نتیجه این نواقص، اتلاف زمان و هزینه برای فعالیتهایی است که ارزش افزودهای ندارند، در حالیکه خرابیهای پرهزینه و با تأثیر بالا که بهطور کامل قابل پیشگیری هستند، همچنان رخ میدهند. این وضعیت به تداوم چرخه نگهداری واکنشی (Reactive Maintenance Cycle) منجر میشود.
در حداقلترین حالت، برنامه نگهداری پیشگیرانه باید بر اساس ۹ اصل یک برنامه PM اثربخش که از RCM استخراج شده است (9 Principles of an Effective PM Program based on RCM) طراحی و پیادهسازی شود. در غیر این صورت، این برنامه به یک سیستم نگهداری پرهزینه و سرشار از اتلاف تبدیل خواهد شد.
جمعبندی نهایی
«چرخه معیوب نگهداری واکنشی (Reactive Maintenance)» یکی از دامهای رایج در بسیاری از سازمانهاست. این چرخه، یک مارپیچ بیوقفه ایجاد میکند که در آن هر وضعیت اضطراری به خرابیهای بیشتر منجر شده و در نهایت یک انباشت کار عقبافتاده (Backlog) بهوجود میآورد که هیچ فضایی برای اجرای بهبودهای راهبردی باقی نمیگذارد. این چرخه نهتنها موجب فرسودگی منابع میشود، بلکه برای کارکنانی که در آن گرفتارند، روحیهفرسا و طاقتگیر است. بااینحال، راه خروج وجود دارد: با اتخاذ راهکارهای اصولی میتوان از دام نگهداری واکنشی رهایی یافت.
کلید شکستن این چرخه در سه گام اساسی نهفته است:
اولویتبندی کارها از طریق برنامهریزی و زمانبندی مؤثر (Planning & Scheduling).
حذف خرابیهای تکراری از طریق حذف عیوب (Defect Elimination).
بهینهسازی برنامه نگهداری پیشگیرانه (Preventive Maintenance Program).
اجرای این سه گام، مسیر گذار از رویکرد واکنشی به یک سیستم نگهداری پیشدستانه و پایدار را فراهم میسازد.
Powered by Froala Editor

.jpg)

درکنار همه و شاید در وهله اول نقش مدیران فنی را در این خصوص نباید فراموش کرد. به جهت موثر بودن راهکارها به نظرم می بایست گام به گام موارد را به سمع و نظر مدیران فنی مربوطه رساند و حمایت و همراهی آنا را نیز پیوست این گامها نمود و دست آخر بازبینی های دوره ای و صحت سنجی انجام امور .